Everybody today uses Hadoop + some more of its ecosystem tools. Let it be Hive / HBase etc. I have been using Hadoop for writing production code from 2012 and for experiments much earlier than that. One thing that I don't see it anywhere is the ability to autoscale the Hadoop cluster elastically. Unlike scaling web servers having all map and reduce tasks full doesn't necessarily translate to CPU / IO metrics spiking on the machines.
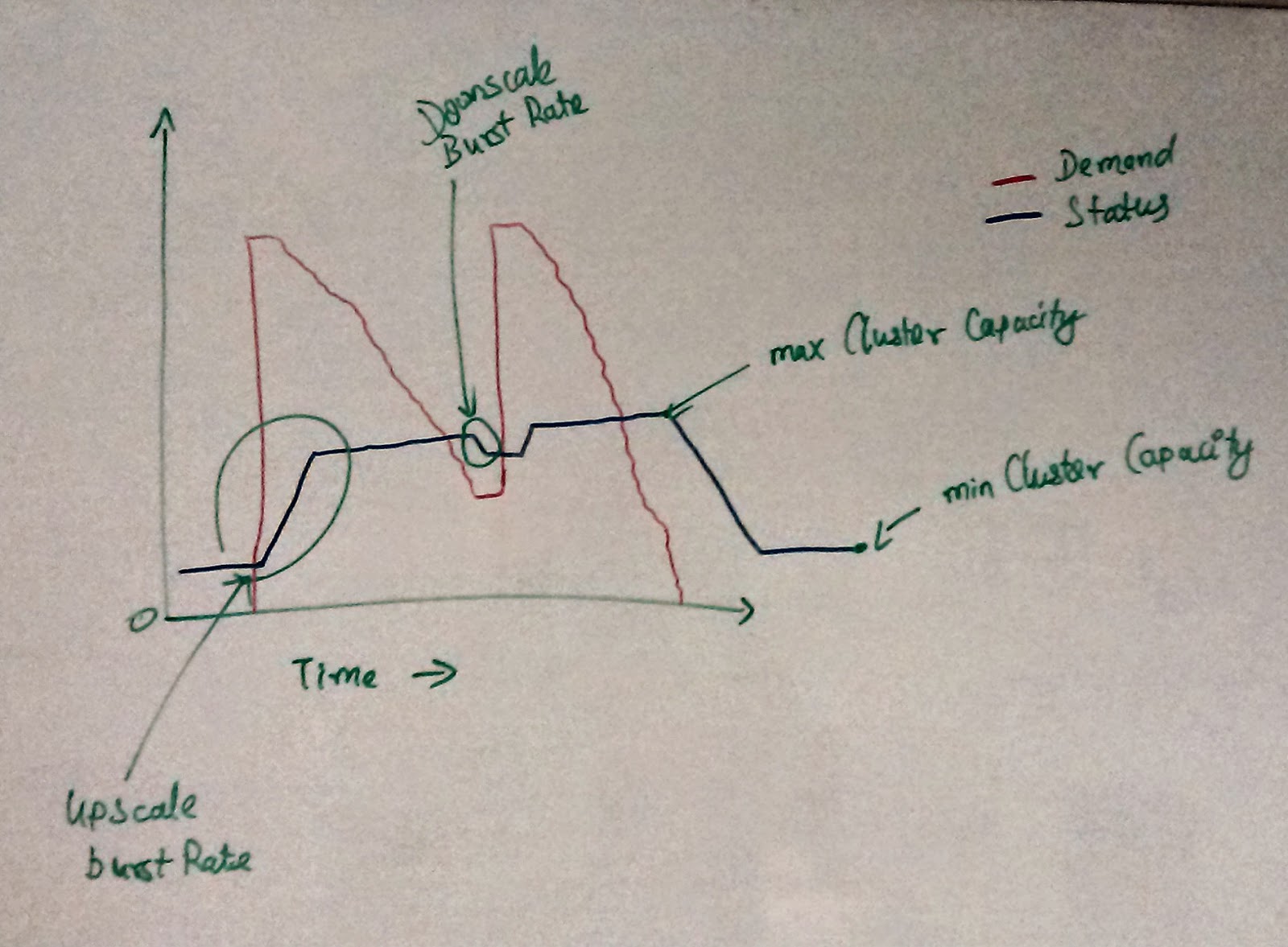
Figure - Usage graph observed from a production cluster
hand drawn on white-board
On this front - Only
Qubole guys have seem to have done some decent work. You should check out their platform if you haven't. It is really super cool. A lot of inspiration for this post have been from using them.
This is one of my hobby project attempt at building just the Autoscaling feature for Hadoop1 clusters if had been part of say Qubole team back in 2012.
In this blog post I talk about the implementation goals and/or hows building this as part of
InMobi's HackDay 2015 (if I get through the selection) or go ahead and build it anyways on that weekend.
For every cluster you would need the following configuration settings
- minNodes - Minimum # of TTs you would always want in the cluster.
- maxNodes - Maximum # of TTs that your cluster would like to use at any point in time.
- checkInterval - Time unit in seconds to check the cluster for compute demand (default - 60)
- hustlePeriod - Time unit in seconds to monitor the demand before we go ahead with upscaling / downscaling the cluster. - (default - 600)
- upscaleBurstRate - Rate at which you want to upscale based on the demand (default- 100%)
- downscaleBurstRate - Rate at which you want to downscale (default - 25%)
- mapsPerNode - # of map slots per TT (default - based on the machine type)
- reducersPerNode - # of reduce slots per TT (default - based on the machine type)
Assumptions
- All the nodes in the cluster are of same type and imageId - easier during upscaling / downscaling.
- All TTs will have Datanodes also along with it
Broad Goals
- Less / No manual intervention at all - We're talking about hands-free scaling and not one click scaling.
- Should have less / no changes in the framework - If we start making forks of Hadoop1 / Hadoop2 to support certain features for autoscaling then most likely we'll have a version lock which is not a pretty thing 1-2 years down the lane.
- Should be configurable - For users willing to dive deeper for configuring their autoscaling they should have options to do that. Roughly translates to being all blue configurations having sensible defaults.
Larger vision is to see if we can make the entire thing modular enough to support any type of scaling.
Please do share your thoughts if you have any on the subject.